Merge 82d7f7b9b3039a39c8b8a55d6f2f553e697e9cc4 into d7eb05b9361febead29a74e71ddffc2ebeff5302
This commit is contained in:
commit
5ac1a6766e
19
examples/langchain-python-langchain-webui/askGradio.py
Normal file
19
examples/langchain-python-langchain-webui/askGradio.py
Normal file
@ -0,0 +1,19 @@
|
||||
import random
|
||||
import gradio as gr
|
||||
from langchain.llms import Ollama
|
||||
|
||||
ollama = Ollama(base_url='http://localhost:11434', model="llama2")
|
||||
|
||||
|
||||
|
||||
|
||||
def random_response(message, history):
|
||||
return ollama(message)
|
||||
|
||||
demo = gr.ChatInterface(random_response, title="Echo Bot")
|
||||
|
||||
if __name__ == "__main__":
|
||||
demo.launch()
|
||||
|
||||
|
||||
|
||||
80
examples/langchain-python-langchain-webui/main.py
Normal file
80
examples/langchain-python-langchain-webui/main.py
Normal file
@ -0,0 +1,80 @@
|
||||
#! /usr/bin/python3.10
|
||||
|
||||
import gradio as gr
|
||||
import sys
|
||||
import os
|
||||
import subprocess
|
||||
from collections.abc import Iterable
|
||||
from langchain.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader, UnstructuredHTMLLoader
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
|
||||
from langchain.chains import RetrievalQA
|
||||
from langchain.llms import Ollama
|
||||
from langchain.vectorstores import FAISS, Chroma
|
||||
from langchain.embeddings import GPT4AllEmbeddings, CacheBackedEmbeddings
|
||||
from langchain.storage import LocalFileStore#, RedisStore, UpstashRedisStore, InMemoryStore
|
||||
|
||||
docsUrl = "/home/user/dev/docs"
|
||||
ollamaModel="llama2"
|
||||
|
||||
def get_ollama_names():
|
||||
output = subprocess.check_output(["ollama", "list"])
|
||||
lines = output.decode("utf-8").splitlines()
|
||||
names = {}
|
||||
for line in lines[1:]:
|
||||
name = line.split()[0].split(':')[0]
|
||||
names[name] = name
|
||||
return names
|
||||
|
||||
names = get_ollama_names()
|
||||
|
||||
def greet(name):
|
||||
global ollamaModel
|
||||
ollamaModel=name
|
||||
return f"{name}"
|
||||
|
||||
dropdown = gr.Dropdown(label="Models available", choices=names, value="llama2")
|
||||
textbox = gr.Textbox(label="You chose")
|
||||
|
||||
def AI_response(question, history):
|
||||
ollama = Ollama(base_url='http://localhost:11434', model=ollamaModel)
|
||||
print(ollamaModel)
|
||||
documents = []
|
||||
for file in os.listdir(docsUrl):
|
||||
if file.endswith(".pdf"):
|
||||
pdf_path = docsUrl + "/" + file
|
||||
loader = PyPDFLoader(pdf_path)
|
||||
documents.extend(loader.load())
|
||||
print("Found " + pdf_path)
|
||||
elif file.endswith('.docx') or file.endswith('.doc'):
|
||||
doc_path = docsUrl + "/" + file
|
||||
loader = Docx2txtLoader(doc_path)
|
||||
documents.extend(loader.load())
|
||||
print("Found " + doc_path)
|
||||
elif file.endswith('.txt') or file.endswith('.kt') or file.endswith('.json'):
|
||||
text_path = docsUrl + "/" + file
|
||||
loader = TextLoader(text_path)
|
||||
documents.extend(loader.load())
|
||||
print("Found " + text_path)
|
||||
elif file.endswith('.html') or file.endswith('.htm'):
|
||||
htm_path = docsUrl + "/" + file
|
||||
loader = UnstructuredHTMLLoader(htm_path)
|
||||
documents.extend(loader.load())
|
||||
print("Found " + htm_path)
|
||||
|
||||
text_splitter = CharacterTextSplitter(chunk_size=32, chunk_overlap=32)
|
||||
all_splits = text_splitter.split_documents(documents)
|
||||
vectorstore = Chroma.from_documents(documents=all_splits, embedding=GPT4AllEmbeddings(embeddings_chunk_size=1000))
|
||||
docs = vectorstore.similarity_search(question)
|
||||
len(docs)
|
||||
qachain=RetrievalQA.from_chain_type(ollama, retriever=vectorstore.as_retriever())
|
||||
reply=str(qachain.run(question))
|
||||
return reply
|
||||
|
||||
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
interface = gr.Interface(fn=greet, inputs=[dropdown], outputs=[textbox], title="Choose a LLM model")
|
||||
chat = gr.ChatInterface(AI_response, title="Put your files in folder " + docsUrl)
|
||||
|
||||
demo.launch(server_name="0.0.0.0", server_port=7860)
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 69 KiB |
25
examples/langchain-python-langchain-webui/readme.md
Normal file
25
examples/langchain-python-langchain-webui/readme.md
Normal file
@ -0,0 +1,25 @@
|
||||
# LangChain Web UI
|
||||
|
||||
A python Gradio web UI using GPT4AllEmbeddings that lets can choose among the installed models
|
||||
|
||||
## Screenshot
|
||||
|
||||
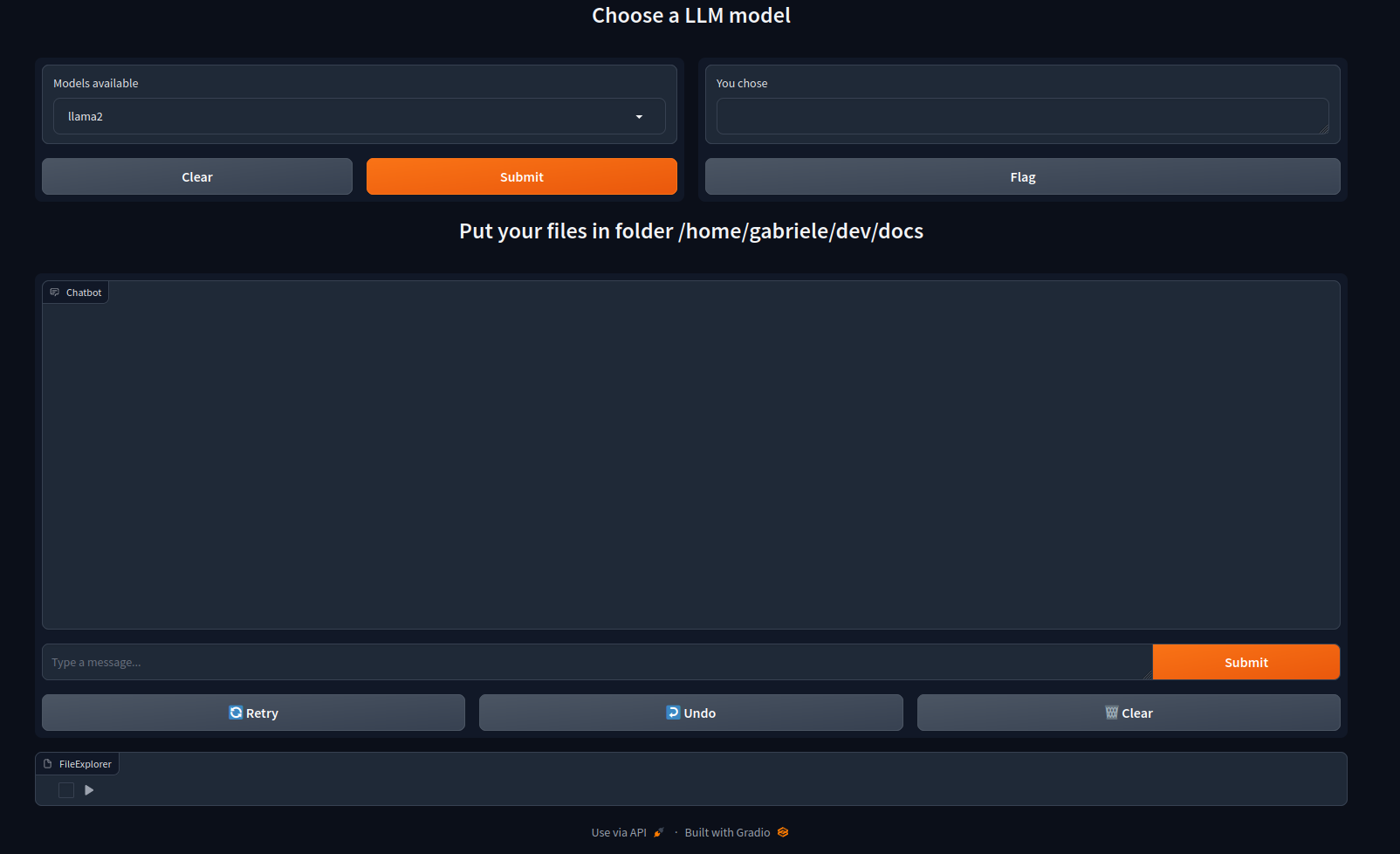
|
||||
|
||||
## Setup
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Run
|
||||
|
||||
```
|
||||
python main.py
|
||||
```
|
||||
|
||||
Running this example will open a web server with port 7860:
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
10
examples/langchain-python-langchain-webui/requirements.txt
Normal file
10
examples/langchain-python-langchain-webui/requirements.txt
Normal file
@ -0,0 +1,10 @@
|
||||
langchain==0.0.313
|
||||
pypdf==3.16.4
|
||||
chromadb==0.4.14
|
||||
tiktoken==0.5.1
|
||||
docx2txt==0.8
|
||||
unstructured==0.10.25
|
||||
gradio==3.50.2
|
||||
Pillow==10.1.0
|
||||
matplotlib==3.8.0
|
||||
numpy==1.23.5
|
||||
Loading…
x
Reference in New Issue
Block a user